Contents
1. Work in Progress: Logic Programming with Names and Binding
2. Implementing Rational Features for Agents in Logic Programming
Work in Progress: Logic Programming with Names and Binding
James Cheney, Cornell University,
jcheney@cs.cornell.eduand,
and Christian Urban, University of Cambridge,
Christian.Urban@cl.cam.ac.uk
In this paper we describe
work in progress on ![]() Prolog, a logic programming language with a built-in
notion of names, binding and unification modulo
Prolog, a logic programming language with a built-in
notion of names, binding and unification modulo ![]() -equivalence.
-equivalence. ![]() Prolog is based on a mild extension of first-order Horn
formulae: instead of the usual first-order terms and first-order
unification, it uses nominal terms and nominal unification introduced in
[3].
Prolog is based on a mild extension of first-order Horn
formulae: instead of the usual first-order terms and first-order
unification, it uses nominal terms and nominal unification introduced in
[3].
Note: This paper is a revised version of [1].
1. Introduction
Logic programming is
particularly suited for implementing inference rules defining relations
over terms. Many interesting examples, however, involve terms with bound
variables and ![]() -equivalence. For example the typing relation for
-equivalence. For example the typing relation for ![]() -terms is often formulated with the inference rules
-terms is often formulated with the inference rules
|
|
|
|
with the implicit
side-condition that in ![]() (a set of type assignments for variables) no variable
has more than one assignment. This side-condition is violated if the third
rule is applied bottom-up and
(a set of type assignments for variables) no variable
has more than one assignment. This side-condition is violated if the third
rule is applied bottom-up and ![]() in the conclusion already contains an assignment for
in the conclusion already contains an assignment for
![]() . In this case the bound variable
. In this case the bound variable ![]() in
in ![]() needs to be renamed to a new
needs to be renamed to a new ![]() so that a type assignment for
so that a type assignment for ![]() can be safely added to
can be safely added to ![]() . It is understood that this renaming does not affect
the meaning of the term, because terms are identified modulo
. It is understood that this renaming does not affect
the meaning of the term, because terms are identified modulo ![]() -equivalence.
-equivalence.
However, this intuitive
account of ![]() -equivalence does not carry over to a correct
declarative implementation in Prolog. For example, if we naïvely implement
the typing rules with the clauses
-equivalence does not carry over to a correct
declarative implementation in Prolog. For example, if we naïvely implement
the typing rules with the clauses
|
member X X::L. |
|
|
|
member X Y::L |
:- |
member X L. |
|
type Gamma (var X) T |
:- |
member (pair X T) Gamma. |
|
type Gamma (app M N) T' |
:- |
type Gamma M (arrow T T'), |
|
|
|
type Gamma N T. |
|
type Gamma (lam X M) (arrow T T') |
:- |
type (pair X T)::Gamma M T'. |
where
X is a (logical) variable,
then we get incorrect answers for ![]() -terms such as
-terms such as ![]() . For this ill-formed term, the naïve implementation
erroneously returns two possible types:
. For this ill-formed term, the naïve implementation
erroneously returns two possible types: ![]() and
and ![]() . Although this problem can be fixed by judicious use of
cut, first-order terms are unwieldy for implementing relations about
syntax with binders correctly.
. Although this problem can be fixed by judicious use of
cut, first-order terms are unwieldy for implementing relations about
syntax with binders correctly.
The traditional solution
for this problem is to use a higher-order logic programming language, such
as ![]() Prolog (see for example [2]), with higher-order terms.
Such languages provide elegant mechanisms for dealing with binders, but
they also introduce new problems: unification for higher-order terms is in
general undecidable and if unifiers exist for a problem they may not be
subsumed by a single most general unifier. Furthermore, inference rules
such as the ones given above are specified using meta-variables (often
also referred to as context-variables, which can be replaced with a term);
using higher-order unification one needs to replace these meta-variables
with function variables and moreover has to explicitly specify the
parameters the function variables depend on. This leads to encodings that
are quite different in form from their intuitive pen-and-paper
counterparts since there dependences are left implicit as much as
possible.
Prolog (see for example [2]), with higher-order terms.
Such languages provide elegant mechanisms for dealing with binders, but
they also introduce new problems: unification for higher-order terms is in
general undecidable and if unifiers exist for a problem they may not be
subsumed by a single most general unifier. Furthermore, inference rules
such as the ones given above are specified using meta-variables (often
also referred to as context-variables, which can be replaced with a term);
using higher-order unification one needs to replace these meta-variables
with function variables and moreover has to explicitly specify the
parameters the function variables depend on. This leads to encodings that
are quite different in form from their intuitive pen-and-paper
counterparts since there dependences are left implicit as much as
possible.
In this paper we shall
present a logic programming language called ![]() Prolog in which one can implement the inference rules
given above correctly as follows:
Prolog in which one can implement the inference rules
given above correctly as follows:
|
type Gamma (var X) T |
:- |
member (pair X T) Gamma. |
|
type Gamma (app M N) T' |
:- |
type Gamma M (arrow T T'), |
|
|
|
type Gamma N T. |
|
type Gamma (lam x.M) (arrow T T') |
/ |
x#Gamma |
|
|
:- |
type (pair x T)::Gamma M T'. |
Posing the queries
· type nil (lam x.(lam x. (var x))) A and
· type nil (lam x.(lam x. (app (var x) (var x))) B
to ![]() Prolog produces the unique answer
Prolog produces the unique answer ![]() for (a), and no answer for (b).
for (a), and no answer for (b).
Two novel features of ![]() Prolog are illustrated by the third clause of
type. First, abstractions
are a built-in notion of
Prolog are illustrated by the third clause of
type. First, abstractions
are a built-in notion of ![]() Prolog; thus we can write
(lam x.M) in which
x is taken from the
syntactic category of names, M
is a variable and lam a
function symbol. This term is intended to unify with any
Prolog; thus we can write
(lam x.M) in which
x is taken from the
syntactic category of names, M
is a variable and lam a
function symbol. This term is intended to unify with any ![]() -abstraction, for example
(lam x.var x),
(lam y.app (var x) (var y))
and so on, where in the first case the unifier is the capturing
substitution
-abstraction, for example
(lam x.var x),
(lam y.app (var x) (var y))
and so on, where in the first case the unifier is the capturing
substitution ![]() . Note that if we had used higher-order unification,
then (lam x.M) does not
unify with (lam x.var x),
because there is no capture-avoiding substitution that makes both terms
equal. Also note that in
. Note that if we had used higher-order unification,
then (lam x.M) does not
unify with (lam x.var x),
because there is no capture-avoiding substitution that makes both terms
equal. Also note that in ![]() Prolog binders have concrete names, which are not
restricted to the scope of the abstraction. These names can be therefore
used in the body of the clause, for example to add
(pair x T) to the context
Gamma. In contrast, in
higher-order abstract syntax binders are anonymous and cannot escape their
scope. So, in
Prolog binders have concrete names, which are not
restricted to the scope of the abstraction. These names can be therefore
used in the body of the clause, for example to add
(pair x T) to the context
Gamma. In contrast, in
higher-order abstract syntax binders are anonymous and cannot escape their
scope. So, in ![]() Prolog, a binder from the head cannot be used in the
body of a clause.
Prolog, a binder from the head cannot be used in the
body of a clause.
Second, freshness
constraints, here x#Gamma,
can be attached to the heads of clauses; the freshness constraint
x#Gamma ensures that the
variable Gamma is not
instantiated with a term containing
x freely. Since the third clause is intended to implement the type
inference rule for ![]() -abstractions, its operational behaviour is given by:
choose fresh names for Gamma,
x,
M,
T and
T' (this is standard in
Prolog-like languages), unify the head of the clause with the goal
formula, apply the resulting unifier to the body of the clause and make
sure that Gamma is not
substituted with a term that contains free occurrences of the fresh name
we have chosen for x.
-abstractions, its operational behaviour is given by:
choose fresh names for Gamma,
x,
M,
T and
T' (this is standard in
Prolog-like languages), unify the head of the clause with the goal
formula, apply the resulting unifier to the body of the clause and make
sure that Gamma is not
substituted with a term that contains free occurrences of the fresh name
we have chosen for x.
2. Nominal terms and nominal unification
To calculate unifiers,
![]() Prolog employs the nominal unification algorithm of
Urban et al. [3], which produces unifiers that make two terms equal modulo
Prolog employs the nominal unification algorithm of
Urban et al. [3], which produces unifiers that make two terms equal modulo
![]() -equivalence. Nominal unification retains the main
advantages of first-order unification: all unification problems are
decidable and solvable problems possess most general unifiers. It makes
use of the notion of possibly capturing substitutions, i.e. substitutions
that allow M to be
substituted with (var x) in
the term (lam x.M) without
introducing a new name for the binder
x, and the notion of name
swapping. A name swapping is a pair of the form
-equivalence. Nominal unification retains the main
advantages of first-order unification: all unification problems are
decidable and solvable problems possess most general unifiers. It makes
use of the notion of possibly capturing substitutions, i.e. substitutions
that allow M to be
substituted with (var x) in
the term (lam x.M) without
introducing a new name for the binder
x, and the notion of name
swapping. A name swapping is a pair of the form ![]() , and if applied for example to the term
, and if applied for example to the term
![]()
gives
![]()
As can be seen the name
swapping acts on all occurrences of
x and y regardless
whether they are bound, free or binding. The crucial point about name
swapping is that it preserves ![]() -equivalence. For instance, consider
-equivalence. For instance, consider ![]() and
and ![]() , which are
, which are ![]() -equivalent. Swapping
-equivalent. Swapping ![]() and
and ![]() results in
results in ![]() and
and ![]() , which are still
, which are still ![]() -equivalent, but naïvely substituting
-equivalent, but naïvely substituting ![]() for
for ![]() results in variable capture in the first term.
results in variable capture in the first term.
Swappings are employed in
the nominal unification algorithm when abstractions are unified. For
example if one unifies the term lam
x.M with lam y.var y,
then M will be instantiated
with the term var x which
can be obtained by applying the swapping ![]() to var y
(written as
to var y
(written as ![]() ). However care needs to be taken if
x occurs freely in the term
to which the swapping is applied. For example the unification problem
). However care needs to be taken if
x occurs freely in the term
to which the swapping is applied. For example the unification problem
![]()
does not have any solution
(just replacing M by the
swapped version of ![]() does not yield two
does not yield two ![]() -equivalent terms). This problem is solved in nominal
unification by freshness constraints, which ensure that possible solutions
respect
-equivalent terms). This problem is solved in nominal
unification by freshness constraints, which ensure that possible solutions
respect ![]() -equivalence. So for solving the unification problem
given above one needs to solve
-equivalence. So for solving the unification problem
given above one needs to solve
![]()
where the first problem
asks whether M and ![]() unify, and the second problem asks whether
x is fresh for
unify, and the second problem asks whether
x is fresh for ![]() , i.e.
, i.e. ![]() cannot contain any free occurrence of
x. Since the latter does not
hold, the unification problem failsas expected.
cannot contain any free occurrence of
x. Since the latter does not
hold, the unification problem failsas expected.
While in the examples above the variable M is unified with ground terms only, nominal unification also solves more general unification problems involving open terms. For this the notion of freshness constraint needs some slight extensionfor the details we refer the reader to [3] which also includes references about a formal verification of the correctness of the nominal unification algorithm using the proof assistant Isabelle.
3.
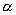 Prolog examples
Prolog examples
Considering the first
experience we gained with ![]() Prolog there is good evidence that abstractions and
freshness constraints from nominal unification provide useful programming
constructs. Consider for example two of the transformations required for
calculating a prenex-normal form of a formula
Prolog there is good evidence that abstractions and
freshness constraints from nominal unification provide useful programming
constructs. Consider for example two of the transformations required for
calculating a prenex-normal form of a formula
![]()
where in the second
transformation ![]() must not contain any free occurrence of
must not contain any free occurrence of ![]() . These transformations can be implemented as the
following clauses.
. These transformations can be implemented as the
following clauses.
|
prenex (and (forall x.P) (forall x.Q)) (forall x.(and P Q)). |
|
prenex (and (forall x.P) Q) (forall x.(and P Q)) / x#Q. |
In the first clause, the
use of nominal unification allows, roughly speaking, to synchronise the
two binders. In effect this clause is applicable for any term of the form
(and (forall y.
) (forall z.
).
What is pleasant about ![]() Prolog is that in this clause no explicit renaming of
the binders is required: it will be done implicitly by the swapping
operation of the unification algorithm. In the second clause, the
freshness constraint x#Q
makes sure that the side-condition placed upon the second transformation
holds. In contrast, in a higher-order abstract syntax encoding, we cannot
explicitly say that a variable must not occur in a term; instead we can
only say that a variable may occur in a term. So, for example, we would
have to make the potential dependences on
x explicit everywhere in
Prolog is that in this clause no explicit renaming of
the binders is required: it will be done implicitly by the swapping
operation of the unification algorithm. In the second clause, the
freshness constraint x#Q
makes sure that the side-condition placed upon the second transformation
holds. In contrast, in a higher-order abstract syntax encoding, we cannot
explicitly say that a variable must not occur in a term; instead we can
only say that a variable may occur in a term. So, for example, we would
have to make the potential dependences on
x explicit everywhere in
![]() Prolog clauses defining prenex transformations:
Prolog clauses defining prenex transformations:
|
prenex (and (forall xP x) (forall xQ x)) (forall x (and (P x) (Q x))). |
|
prenex (and (forall xP x) Q) (forall x(and (P x) Q)). |
Another example is given
below. It implements the capture-avoiding substitution of a variable in a
![]() -term[1].
-term[1].
|
id X X. |
|
|
|
subst (var X) X T T. |
|
|
|
subst (var Y) X T (var Y) |
:- |
not(id X Y). |
|
subst (app M N) X T (app M' N') |
:- |
subst M X T M', subst N X T N'. |
|
subst (lam y.M) X T (lam y.M') |
/ |
y#T,X |
|
|
:- |
subst M X T M'. |
Given this program, posing
the query subst (lam (x. var y)) y
(var x) M yields the result ![]() where x'
is chosen freshly during proof search.
where x'
is chosen freshly during proof search.
Our final example is the
definition of evaluation for ![]() -terms. We first define a relation which expresses
-terms. We first define a relation which expresses ![]() -reduction:
-reduction:
|
beta (app (lam (x.E)) E') R |
:- |
subst E x E' R. |
Now we define relations
step that express one-step
reduction of ![]() -terms, and steps,
the reflexive, transitive closure of
step:
-terms, and steps,
the reflexive, transitive closure of
step:
|
step M M' |
:- |
beta M M'. |
|
step (app M N) (app M' N) |
:- |
step M M'. |
|
step (app M N) (app M N') |
:- |
step N N'. |
|
step (lam (x.M)) (lam (x.M')) |
:- |
step M M'. |
|
steps M M. |
|
|
|
steps M M' |
:- |
step M M', steps M' M''. |
>From the experience we
gained so far, all inference rules involving ![]() -terms can in
-terms can in ![]() Prolog be implemented nearly one-to-one. We wish to
stress, however, that
Prolog be implemented nearly one-to-one. We wish to
stress, however, that ![]() Prolog is not limited to defining relations on
Prolog is not limited to defining relations on ![]() -terms. We have chosen the
-terms. We have chosen the ![]() -calculus as an example because it well-known and the
issues raised by binding and capture-avoiding substitution are widely
appreciated. However,
-calculus as an example because it well-known and the
issues raised by binding and capture-avoiding substitution are widely
appreciated. However, ![]() Prolog can also be used to write programs about
languages with other forms of binding, provided these forms admit
Prolog can also be used to write programs about
languages with other forms of binding, provided these forms admit ![]() -equivalence. Some examples include concurrency calculi
such as the
-equivalence. Some examples include concurrency calculi
such as the ![]() -calculus and the Calculus of Mobile Ambients, in which
names can be bound but are not subject to substitution by other (process)
terms, only renaming. Another example is modeling imperative languages
like C, in which variables serve a dual role as references to memory cells
and their contents. Also, freshness constraints and fresh-name generation
may be of interest in their own right, for example in modeling fresh-nonce
generation in security protocols.
-calculus and the Calculus of Mobile Ambients, in which
names can be bound but are not subject to substitution by other (process)
terms, only renaming. Another example is modeling imperative languages
like C, in which variables serve a dual role as references to memory cells
and their contents. Also, freshness constraints and fresh-name generation
may be of interest in their own right, for example in modeling fresh-nonce
generation in security protocols.
4. Conclusion
Currently, we have
implemented a prototype interpreter for ![]() Prolog that permits user-defined datatypes and
polymorphically typed Horn clauses. Work on verifying the correctness of
Prolog that permits user-defined datatypes and
polymorphically typed Horn clauses. Work on verifying the correctness of
![]() Prologs proof search algorithm relative to Nominal
Logic and on optimizing the nominal unification algorithm is in progress.
In the future, we plan to adapt more advanced logic program analyses for
Prologs proof search algorithm relative to Nominal
Logic and on optimizing the nominal unification algorithm is in progress.
In the future, we plan to adapt more advanced logic program analyses for
![]() Prolog programs, such as mode, determinism, and
termination analyses. Many interesting properties of languages can be
framed in terms of such properties on relations; for example unicity and
decidability of typechecking can be expressed in terms of determinism and
termination of an appropriate moding of the typing relation. Eventually we
wish to support general inductive theorem proving about
Prolog programs, such as mode, determinism, and
termination analyses. Many interesting properties of languages can be
framed in terms of such properties on relations; for example unicity and
decidability of typechecking can be expressed in terms of determinism and
termination of an appropriate moding of the typing relation. Eventually we
wish to support general inductive theorem proving about ![]() Prolog programs. We believe that this will lead to
better tools for computer-assisted reasoning about properties of
languages.
Prolog programs. We believe that this will lead to
better tools for computer-assisted reasoning about properties of
languages.
Acknowledgements:
Dominik Wee implemented a preliminary version of ![]() Prolog as a thesis project. We thank Marinos Georgiades
who invited us to write this paper for the CoLogNet newsletter.
Prolog as a thesis project. We thank Marinos Georgiades
who invited us to write this paper for the CoLogNet newsletter.
[1] J. Cheney and C. Urban. System description: alpha-Prolog, a fresh approach to logic programming modulo alpha-equivalence. In J. Levy, M. Kohlhase, J. Niehren, and M. Villaret, editors, Proceedings of the 17th International Workshop on Unification, UNIF03, pages 1519, Valencia, Spain, June 2003. Departamento de Sistemas Informaticos y Computacion, Universidad Politecnica de Valencia. Technical Report DSIC-II/12/03.
[2] Gopalan Nadathur and Dale Miller. Higher-order logic programming. In D. Gabbay, C. Hogger, and A. Robinson, editors, Handbook of Logic in AI and Logic Programming, Volume 5: Logic Programming. Oxford, 1986.
[3] C. Urban, A. M. Pitts, and M. J. Gabbay. Nominal unification. In M. Baaz, editor, Computer Science Logic and 8th Kurt Godel Colloquium (CSL03 & KGC), Lecture Notes in Computer Science, Vienna, Austria, 2003. Springer-Verlag. To appear.
Footnotes:
1not
is the usual negation-by-failure.
Implementing Rational Features for Agents in Logic Programming
Luís
Moniz Pereira[2]
lmp@di.fct.unl.pt
Universidade Nova de Lisboa
Outline
- Implementations of rational agent features[3].
-
Overview of selected
implemented features
- Dynamic Logic Programming
- Evolving Logic Programs
- Reasoning Integration
- Semantic Web application
- Implemented features left out: Belief Revision, Aduction
- W4 project: Well-founded semantics for the World Wide Web
- Conclusion
Introduction
We have implemented the following Rational Agent Features:
Some of these are further detailed below. All can be followed up on via their respective hyperlink.
DLP is a semantics for updates of LPs by LP rules. It guarantees that most recent rules are set in force, and previous rules valid by inertia insofar as possible, i.e. are kept for as long as they do not conflict with more recent ones. Originally, in DLP default negation is treated as in the stable models semantics of generalized programs. Now it is also defined for the WFS.
EVOLP is a Logic Programming language for: specifying evolution of knowledge bases; allowing dynamic updates of specifications; capable of dealing with external events; dealing with sequences of sets of EVOLP rules.These rules are generalized LP rules (i.e. possibly with nots in heads) plus the special predicate assert/1, that can appear both in heads or bodies of rules. The argument of assert/1 can be a full-blown EVOLP rule. The meaning of a sequence of update rules is given by sequences of models. Each sequence determines a possible evolution of the KB. Each model determines what is true after a number of evolution steps (i.e. a state) in the sequence:
-
A first model in a sequence is built by computing the semantics of the first EVOLP program, where assert/1 is as any other predicate.
-
If assert(Rule) is true at some state, then the KB must be updated with Rule.
-
This updating of the KB, and the computation of the next model in the sequence, is done as in DLP.
An example application concerns a personal assistant agent for email management able to: Perform basic actions of sending, receiving, deleting messages; Storing and moving messages between folders; Filtering spam messages; Sending automatic replies and forwarding; Notifying the user of special situations.
All of this dependent on user specified criteria, and where the specification may change dynamically[4].
We can integrate within the same logic programming framework incomplete, uncertain and paraconsistent reasoning forms. Furthermore, our semantics are able to detect the dependencies on contradiction[5]. Existing embeddings of other formalisms into our fremework are: Ordinary Horn clauses; Generalized Annotated Logic Programs; Fuzzy Logic Programs; Probabilistic Deductive Databases; Weighted Logic Programs and Statistical Defaults; Hybrid Probabilistic Logic Programs; Possibilistic Logic Programs; Quantitative Rules; Multi-adjoint Logic Programming; Rough Sets.
Our XML tools:
Non-validating XML parser with support for XML Namespaces, XML Base, complying with the recommendations of XML Info Sets. Reads US-ASCII, UTF-8, UTF-16, and ISO-8859-1 encodings.
-
Converter of XML to Prolog terms.
-
RuleML compiler for the Hornlog fragment, extended with default and explicit negation.
-
Query evaluation procedures for Paraconsistent Well-founded Semantics with Explicit Negation.
These and the tools mentioned below, enable our group with possibilities regarding Semantic Web Applications of Logic Programming. This is being pursued in the wider context of the REWERSE NoE submitted to the FP6 (under evaluation but with good chances of approval, and having already passed the first hurdle). Our Logic Programming and the Semantic Web tools:
-
RuleML standards.
-
Implementation of Prolog based standard XML tools, namely a fully functional RuleML compiler for the Horn fragment with two types of negation (default and explicit).
-
Evolution and updating of knowledge bases. The existing implementations are being integrated with RuleML.
-
Semantics of logic programming. Supporting uncertain, incomplete, and paraconsistent reasoning (based on Well-founded Semantics and Answer Sets).
-
Development of advanced Prolog compilers (GNU-Prolog and XSB).
-
Development of distributed tabled query procedures for RuleML.
-
Constraint Logic Programming.
The W4 project: Well-founded semantics for the WWW
The W4 project aims at developing Standard Prolog inter-operable tools for supporting distributed, secure, and integrated reasoning activities in the Semantic Web. The project goals are:
-
Development of Prolog technology for XML, RDF, and RuleML.
-
Development of a General Semantic framework for RuleML including default and explicit negation, supporting uncertain, incomplete, and paraconsistent reasoning.
-
Development of distributed query evaluation procedures for RuleML, based on tabulation, according to the previous semantics.
-
Development of Dynamic Semantics for evolution/update of Rule ML knowledge bases.
-
Integration of different semantics in Rule ML (namely, Well-founded Semantics, Answer Sets, Fuzzy Logic Programming, Annotated Logic Programming, and Probabilistic Logic Programming).
Why have we chosen the Well-founded Semantics with tabling? Because:
-
THE adopted semantics for definite, acyclic and (locally) stratified logic programs.
-
Defined for every normal logic program, i.e. with default negation in the bodies.
-
Polynomial data complexity.
-
Efficient existing implementations, namely the SLG-WAM engine implemented in XSB. Good structural properties.
-
It has an undefined truth-value...
-
Many extensions exist over WFS, capturing paraconsistent, incomplete and uncertain reasoning.
-
Update semantics via Dynamic Logic Programs.
-
It can be readily "combined" with DBMSs, Prolog, and Stable Models engines.
-
The existence of an undefined logical value is fundamental. While waiting for the answers to a remote goal invokation it can be assumed that its truth-value is undefined, and proceed the computation locally. Loops through default negation are dealt with in XSB, via goal suspension and resume operations.
-
Tabling IS the right, successful, and available implementation technique to ensure better termination properties and polynomial complexity. Tabling is also a good way to address distributed query evaluation of definite and normal logic programs.
The major guidelines of the project are:
-
Tractability of the underlying reasoning machinery.
-
Build upon well-understood existing technology and theory, and widely accepted core semantics.
-
General enough to accommodate and integrate several major reasoning forms.
-
Should extend definite logic programming (Horn clauses). Desirable integration with (logic) functional languages.
-
Most of the reasoning should be local (not very deep dependencies among goals at different locations).
-
Fully distributed architecture, resorting to accepted standards, recommendations and protocols. Indeed, we have implemented and defined a general and open architecture for distributed tabled query-evaluation of definite logic programs. It has a low message complexity overhead. The architecture assumes two types of main components: table storage clients and prover clients. It addresses the issue of table completion by resorting to known termination detection distributed algorithms. It can immediately be extended to handle stratified negation.
The construction of prototypical systems depends on the definition of: Syntactic extensions (apparently, not very difficult); Goal invokation method (Namespaces, XLinks, SOAP, etc.) ; Selection of distributed query evaluation algorithms and corresponding protocols; Formatting of answers and substitutions (should be XML documents); Integration with ontologies. Further applications, testing, and evaluation is required for the construction of practical systems.
Conclusion
In our opinion, Well-founded semantics should be a major player in RuleML, properly integrated with Stable Models. A full-blown theory is available for important extensions of standard WFS/SMs, addressing many of the open issues of the Semantic Web. Most extensions resort to polynomial program transformations, namely those for evolution and update of knowledge bases. Can handle uncertainty, incompleteness, and paraconsistency. Efficient implementation technology exists, and important progress has been made in distributed query evaluation. An open, fully distributed, architecture is being proposed.
-
An updated summary of a presentation at Logic-Based Agent Implementation, An AgentLink/CologNet Symposium, 3rd February, 2003, Barcelona, España. This work has been developed with contributions by (cf. publications): João Alcântara, José Júlio Alferes, António Brogi, Carlos Damásio, João Leite, Luís Moniz Pereira, Teodor Przymusinski, Halina Przymusinska, Paulo Quaresma.
-
E-mail: lmp@di.fct.unl.pt URL: http://centria.di.fct.unl.pt/~ lmp
-
 Available
at
http://centria.fct.unl.pt/~jja/updates/
Available
at
http://centria.fct.unl.pt/~jja/updates/ -
Cf. J. J. Alferes, A. Brogi, J. A. Leite, L. M. Pereira, Logic Programming for Evolving Agents, Cooperative Information Agents (CIA0'3), Helsinki, Finland, August 2003. And, by the same authors, An Evolvable Rule-Based E-mail Agent (submitted).
-
J. Alcântara, C. V. Damásio, L. M. Pereira, An Encompassing Framework for Paraconsistent Logic Programs, Journal of Applied Logic, to appear, 2003. C. V. Damásio, L. M. Pereira, Hybrid Probabilistic Logic Programs as Residuated Logic Programs, Special issue on Logics in Artificial Intelligence, Studia Logica, 72(2):113-118, 2002.